
The frustration of dealing with a bad app process termination can be overwhelming. Not only can it disrupt your workflow, but it can also lead to data loss, corruption, or even system crashes. However, there are ways to handle this situation effectively and minimize the damage.
Firstly, it's essential to understand that a bad app process termination can occur due to various reasons such as a software bug, compatibility issues, or system resource constraints. Whatever the reason, the goal is to resolve the issue quickly and efficiently.
In this article, we will discuss five ways to handle a bad app process termination, providing you with practical tips and techniques to help you navigate this situation.
Understanding the Importance of Process Termination
Before we dive into the solutions, let's take a moment to understand the significance of process termination in the context of app development and system management.
Process termination is a critical aspect of system resource management. When an app process terminates, it frees up system resources such as memory, CPU, and I/O, allowing other processes to run smoothly. However, a bad app process termination can lead to resource leaks, causing system performance to degrade over time.
1. Identify the Root Cause of the Issue
To handle a bad app process termination effectively, it's crucial to identify the root cause of the issue. This involves analyzing system logs, crash dumps, and other diagnostic data to determine the underlying reason for the termination.
Some common causes of bad app process termination include:
- Software bugs or defects
- Compatibility issues with other apps or system components
- Resource constraints such as memory or CPU overload
- System configuration errors or inconsistencies
By identifying the root cause of the issue, you can develop a targeted solution to address the problem and prevent similar terminations in the future.
Analyzing System Logs and Crash Dumps
To analyze system logs and crash dumps, you can use various tools and techniques such as:
- Log analysis software to parse and interpret system logs
- Crash dump analysis tools to examine the contents of crash dumps
- Debugging tools to step through code and identify errors
By using these tools and techniques, you can gain valuable insights into the root cause of the bad app process termination and develop a plan to address the issue.

2. Implement Error Handling and Recovery Mechanisms
Another way to handle a bad app process termination is to implement error handling and recovery mechanisms. This involves designing and implementing robust error handling mechanisms that can detect and respond to errors in a controlled and predictable manner.
Some common error handling and recovery mechanisms include:
- Try-catch blocks to catch and handle exceptions
- Error handling functions to log and report errors
- Recovery mechanisms such as rollback or restart to restore system state
By implementing error handling and recovery mechanisms, you can minimize the impact of a bad app process termination and ensure that the system remains stable and functional.
Best Practices for Error Handling and Recovery
To implement effective error handling and recovery mechanisms, follow these best practices:
- Use try-catch blocks to catch and handle exceptions
- Log and report errors to facilitate debugging and analysis
- Implement recovery mechanisms such as rollback or restart to restore system state
- Test and validate error handling and recovery mechanisms to ensure effectiveness
By following these best practices, you can develop robust error handling and recovery mechanisms that can handle bad app process terminations effectively.

3. Use Monitoring and Debugging Tools
Monitoring and debugging tools can help you detect and diagnose bad app process terminations. These tools can provide valuable insights into system behavior and performance, allowing you to identify and address issues before they become critical.
Some common monitoring and debugging tools include:
- System monitoring software to track system performance and resource utilization
- Debugging tools to step through code and identify errors
- Log analysis software to parse and interpret system logs
By using monitoring and debugging tools, you can detect and diagnose bad app process terminations quickly and effectively.
Best Practices for Monitoring and Debugging
To use monitoring and debugging tools effectively, follow these best practices:
- Use system monitoring software to track system performance and resource utilization
- Use debugging tools to step through code and identify errors
- Use log analysis software to parse and interpret system logs
- Test and validate monitoring and debugging tools to ensure effectiveness
By following these best practices, you can develop a robust monitoring and debugging strategy that can detect and diagnose bad app process terminations effectively.

4. Optimize System Configuration and Resources
Optimizing system configuration and resources can help prevent bad app process terminations. This involves ensuring that system resources such as memory, CPU, and I/O are allocated and configured effectively.
Some common optimization techniques include:
- Resource allocation and deallocation to ensure efficient resource utilization
- System configuration tuning to optimize system performance
- Resource monitoring to detect and respond to resource constraints
By optimizing system configuration and resources, you can prevent bad app process terminations and ensure that the system remains stable and functional.
Best Practices for System Optimization
To optimize system configuration and resources effectively, follow these best practices:
- Allocate and deallocate resources efficiently to minimize waste and reduce the risk of resource constraints
- Tune system configuration to optimize system performance and resource utilization
- Monitor system resources to detect and respond to resource constraints
- Test and validate system optimization techniques to ensure effectiveness
By following these best practices, you can develop a robust system optimization strategy that can prevent bad app process terminations and ensure system stability and performance.

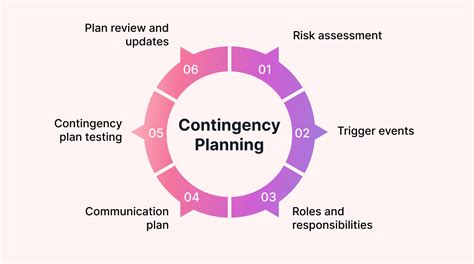
5. Develop a Contingency Plan
Finally, developing a contingency plan can help you respond to bad app process terminations effectively. This involves identifying potential risks and developing strategies to mitigate them.
Some common contingency planning techniques include:
- Risk assessment to identify potential risks and threats
- Development of mitigation strategies to address identified risks
- Testing and validation of contingency plans to ensure effectiveness
By developing a contingency plan, you can respond to bad app process terminations quickly and effectively, minimizing the impact on system stability and performance.
Best Practices for Contingency Planning
To develop a contingency plan effectively, follow these best practices:
- Conduct a thorough risk assessment to identify potential risks and threats
- Develop mitigation strategies to address identified risks
- Test and validate contingency plans to ensure effectiveness
- Review and update contingency plans regularly to ensure relevance and effectiveness
By following these best practices, you can develop a robust contingency plan that can respond to bad app process terminations effectively and minimize the impact on system stability and performance.
Gallery of App Process Termination


FAQ Section
What is a bad app process termination?
+A bad app process termination is an unexpected or unplanned termination of an app process, which can cause system instability and performance issues.
What are the common causes of bad app process terminations?
+The common causes of bad app process terminations include software bugs or defects, compatibility issues with other apps or system components, resource constraints, and system configuration errors or inconsistencies.
How can I handle a bad app process termination?
+You can handle a bad app process termination by identifying the root cause of the issue, implementing error handling and recovery mechanisms, using monitoring and debugging tools, optimizing system configuration and resources, and developing a contingency plan.